

How To Get Past Onlyfans Paywall
How To Bypass Any Paywall For Free
Imagine you're on Wall Street Journal and you want to read this article:
Kind of important in my opinion, but as soon as you read a few words, you're blocked by this paywall:
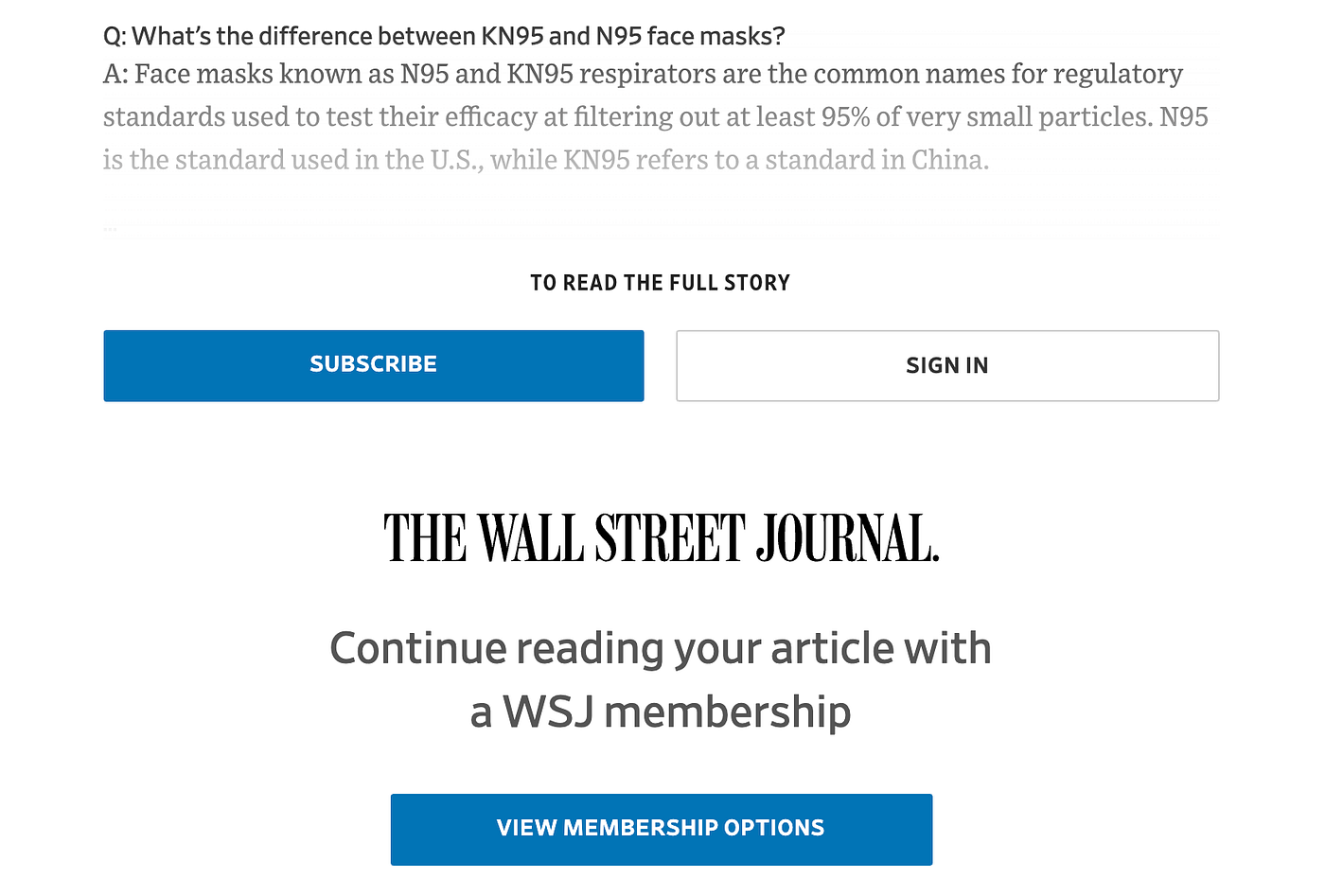
And you would subscribe, but $29.99 per month is a little steep for basic coronavirus info and news.
So, today, we're going to talking about bypassing subscription paywalls with JavaScript.
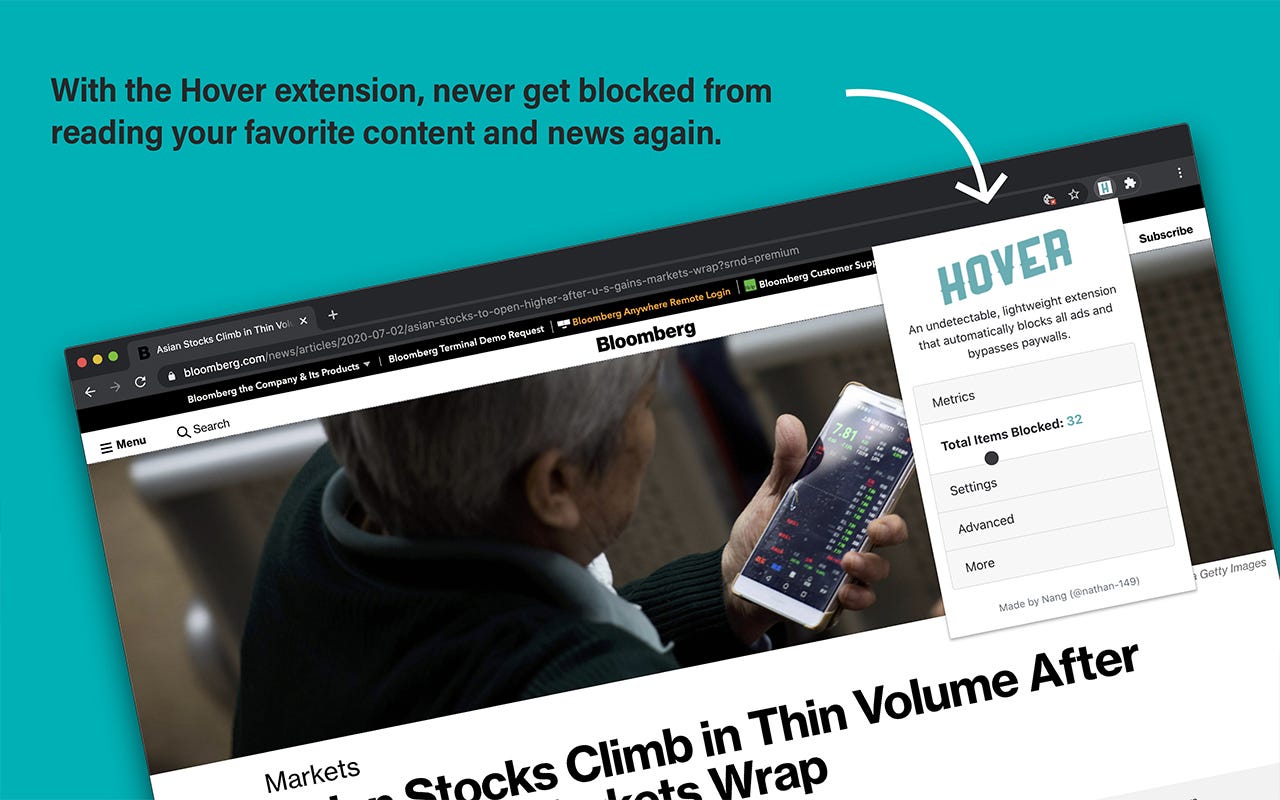
If you're not up for spending 100+ hours coding a fully functional Chrome extension to do this, save time by just adding this free extension, called Hover. It got taken down from the Chrome Web Store, but you can still install it fully from Github (just scroll down to the Install instructions :) ).
It bypasses paywalls on pretty much all sites, including Medium, Business Insider, New York Times, Bloomberg, Quora, etc. and is the most effective method of bypassing paywalls on the market right now.
This is the extension in action, on Medium:

We'll go over how paywalls work, the three main ways of bypassing them, and the code to do so.
This is for educational purposes only. Please never violate the Terms and Services of any website.
So how do paywalls work?
A paywall is just a HTML element that blocks content behind it:
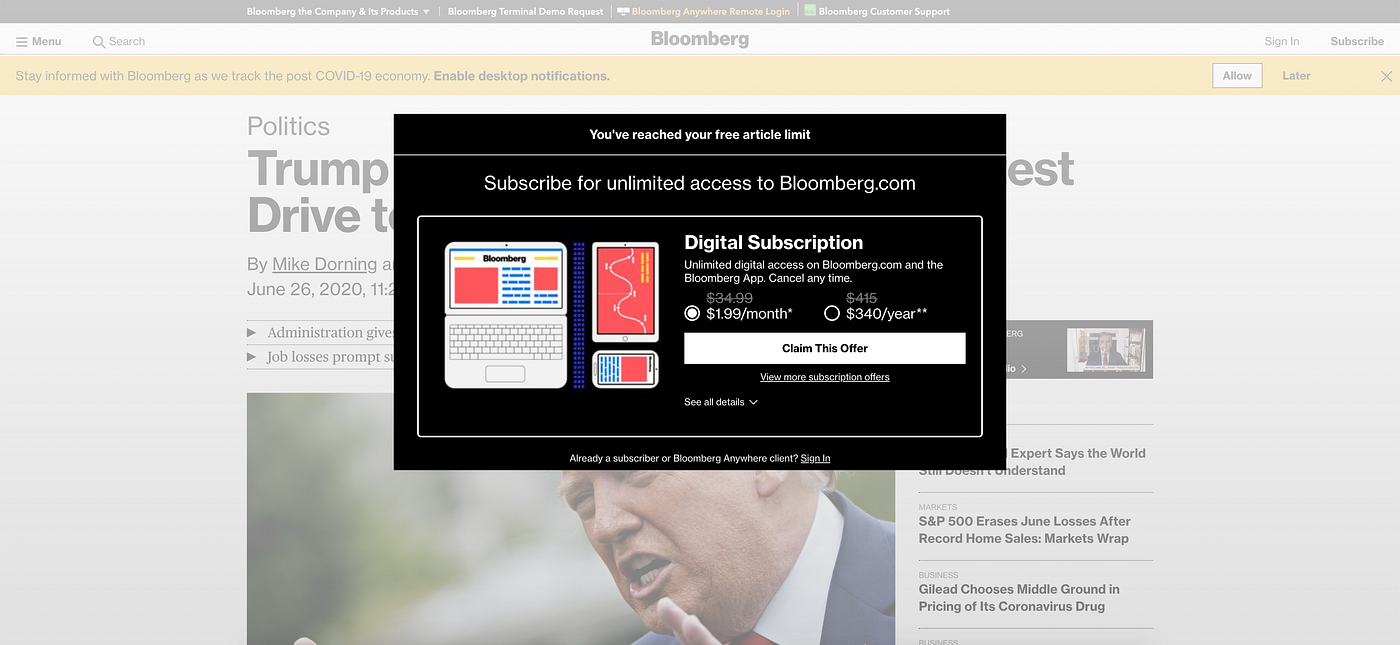
It pops up when you're not subscribed to the site you're on and are all out of free reads (usually 5–10 for life). You can't click outside of it, or scroll through the article. For a lot of people that tried to read this, there was probably a paywall on this article.
Some sources instruct you to simply delete the paywall within the browser by: Right Click Paywall-> Inspect Element -> Click on the main div of the Paywall -> Delete (using delete key). While this does technically get rid of the paywall, it doesn't work on 99% of websites because of two reasons. First, the article usually doesn't load past what's shown behind the paywall — so, you pretty much can only read the headline and the first line of the article. Second, the sites can detect when the paywall gets deleted, so even if you managed to scroll down, the paywall will pop back up within seconds. How unfortunate.
But don't worry, that's what I'm here for. After quite a bit of research and inspecting the actual sites' paywalls to see how they worked, I found three main, effective ways to bypass pretty much any paywall.
The three main ways of bypassing paywalls are:
- Rerouting the Header's Referrer
- Spoofing our machine as a Google Adbot
- Disabling all Cookies
Bypassing paywalls takes one of these three method, depending on the site. For example, Medium's paywall can only be bypassed by rerouting the header's referer to Twitter. On the other hand, New York Times' paywall can only be bypassed by blocking cookies. Let's discuss each of these methods.
Rerouting the Header's Referer
A lot of sites that require subscriptions will allow people to read their article if they come from a social media site, in order to gain new users. For example, if a Medium article is shared on Twitter, Medium will allow everyone who clicks on the article to read it, no matter what — because it's a new, potential customer.
So, one way to bypass the paywall is to tell the site that we came from a social media site, such as Facebook or Twitter.
We can do this by changing the "Referer" part of the Header. When you visit any website, you send them a Header, which contains information such as your browser cookies, your IP address, etc. The "Referer" part of the Header is what refered you to the site. If you saw a Medium article on Twitter, and clicked the link to head to Medium, the referer would be "https://t.co/" (or Twitter).
With JavaScript, we can do this by changing the referer to https://t.co/ by doing within an extension:
//This is a JavaScript file that is added as a background script through in a browser extension function changeCookies(details) { //Redirect Referer details.requestHeaders = details.requestHeaders.filter(function(header) { if(header.name === "Referer") return false return true }) details.requestHeaders.push({ "name": "Referer", "value": "https://t.co/" }) console.log("Changed Header to Twitter") return {requestHeaders: details.requestHeaders}; } //Add listener chrome.webRequest.onBeforeSendHeaders.addListener(changeCookies, { urls: ["<all_urls>"], types: ["main_frame"], }, ["requestHeaders", "blocking", "extraHeaders"] );
This will get past around 1/3 of paywalls, including Medium, Towards Data Science, etc.
Spoofing our machine as a Google Crawler
Most sites want to comply with Google's crawler, which will scan websites and all of their contents. So, if a site has a paywall up, the crawler will not be able to scan its contents. I'm not entirely sure, but my guess is that this will affect the website's ability to show up on Google's search results.
So, another way of bypassing paywalls is to tell the site that we are a Google crawler. We can do this by changing the "User-Agent" and "X-Forwarded-For" parts of the Header, like this:
//This is a JavaScript file that is added as a background script through in a browser extension function spoofCrawler(details) { //Spoof our device as a Google Crawler var google_adbot_UA = "AdsBot-Google (+http://www.google.com/adsbot.html)" details.requestHeaders = details.requestHeaders.filter(function(header) { if(header.name === "User-Agent" || header.name === "X-Forwarded- For") { return false } return true }) details.requestHeaders.push({ "name": "User-Agent",
"value": google_adbot_UA }) details.requestHeaders.push({ "name": "X-Forwarded-For",
"value": "66.102.0.0" }) console.log("Spoofed as Google crawler") return {requestHeaders: details.requestHeaders}; } //Add listener chrome.webRequest.onBeforeSendHeaders.addListener(spoofCrawler, { urls: ["<all_urls>"], types: ["main_frame"], }, ["requestHeaders", "blocking", "extraHeaders"] );
This will get past most of the paywalls, including , Chicago Tribune, Quora, etc.
Disabling All Cookies
Some websites, like Bloomberg and New York Times, have paywalls that can't be bypassed with either of the previously mentioned strategies. So, the last thing we can do is disable all cookies. This is the least ideal approach, because this means you can't log in or have a history of reads, etc. However, this is the only way I could get past paywalls on some of the edge case websites (some of which happen to be very popular).
These sites allow you ~5 free articles to read to get you enticed, before blocking you from all articles with a paywall. But how does it keep track of how many articles you've read? Cookies.
Cookies are small bits of information stored on your browser that a website can access. So, if we disable cookies, sites by default assume this is the first time you are visiting their site, and will allow you to read articles.
It's very important that we disable cookies, and not delete them. If we delete the cookies, the site will detect this and block us from accessing the article.
To disable cookies, we can change the chrome settings, like:
//This is a JavaScript file that is added as a background script through in a browser extension function disableCookies(details) { root = extractRootWebsite(details.url) rootSearch = "*://*." + root + "/*" //Set Cookie Permission if necessary chrome.contentSettings.cookies.set({ 'primaryPattern': rootSearch, 'setting': 'block' }); console.log("Disabled Cookies") } //Add listener chrome.webRequest.onBeforeSendHeaders.addListener(disableCookies, { urls: ["<all_urls>"], types: ["main_frame"], }, ["requestHeaders", "blocking", "extraHeaders"] );
This will get past the last few edge cases of paywalls, including New York Times, Bloomberg, and Wall Street Journal.
Thanks for reading, hope you enjoyed the read! Let me know if you have any questions and have a great day! :)
How To Get Past Onlyfans Paywall
Source: https://medium.datadriveninvestor.com/how-to-bypass-any-paywall-for-free-df87832cbff7
Posted by: michaelaskins.blogspot.com
0 Response to "How To Get Past Onlyfans Paywall"
Post a Comment